Pythagorean Win-Loss
This article courtesy of Graham MacAree from StatCorner.
It was Bill James who first noticed the non-linear relationship between runs scored, runs allowed, and wins. It turned out to be relatively easy to predict a team’s win-loss record using a simple formula, which very closely resembles trigonometry’s Pythagorean Theorem (and I apologise for actually having math in this one):
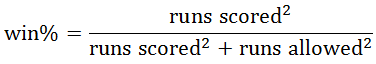
The formula has been updated frequently (generally by changing the exponent) to match empirical results, but there’s a statistical reason for the relationship as well, which is too complex to go into without getting into some serious maths. Regardless, what we need to know for now is that there’s both an empirical and logical relationship between runs scored, runs allowed, and wins, and they agree down to some very small details. Pythagorean expectation goes by other names; notably ‘Pythaganport’ and ‘Pythagenpat’. These are both more accurate versions of the original.
Barking Up The Wrong Tree
Teams whose real winning percentages exceed their expected winning percentages are often referred to as ‘lucky’, and teams who do the opposite are ‘unlucky’. This is a crutch, and it’s far from statistically rigorous. We should not pretend to be able to extract true talent level from two variables alone, and it’s clear that ‘luck’ strikes far more deeply than in simple runs scored and runs allowed in a season. A team with an expected winning percentage of .500 and an actual record of 77-85 is not ‘really’ an 81-win team, although it is true that deviations from pythagorean win-loss are subject to regression. While pure pythagorean expectancy is probably a better way of gauging a team than actual wins and losses, we have some far more informative tricks up our sleeve (we’ll get to them in good time), and so there’s no reason to assume that we’re getting the whole truth from runs scored and runs allowed alone. The idea of pythagorean ‘luck’ is a quick rule of thumb and nothing more.
Another commonly held belief about pythagorean expectation is that its function is to predict wins and losses given the runs scored/runs allowed data. This is not true: it is merely a statement of a relationship, and it’s very important not to forget that. There is no need for pythagorean expectancy to take into account run distribution, or bullpen WPA, or any other input in order to increase its predictive value. Doing so detracts from the central relationship, the very core of what makes pythagorean expectancy useful.
So What’s It For?
If you shouldn’t use pythagorean expectancy to guess at team talent, and you probably shouldn’t refine it to more accurately ‘retro-predict’ actual wins, what exactly is the point of learning about it?
The quick answer is that you can use it to predict wins given expected runs scored and against, perhaps in a projection system. The longer and better answer is that you can use it to derive our win-run conversion. It’s stunningly elegant, really. Without this relationship it would be impossible to look at player value without a statistic that didn’t inherently include wins above some benchmark. If the game state is the heart of most of the advanced statistics, pythagorean expectancy is the soul.
Piper was the editor-in-chief of DRaysBay and the keeper of the FanGraphs Library.
” While pure pythagorean expectancy is probably a better way of gauging a team than actual wins and losses, we have some far more informative tricks up our sleeve (we’ll get to them in good time),”
The “(we’ll get to them in good time)” is vague, unhelpful and never referred to again. [Also it sounds didactic and patronizing to me.]
I assume it refers to win-run conversion, but a reader shouldn’t have to make that assumption.